Question 1 -
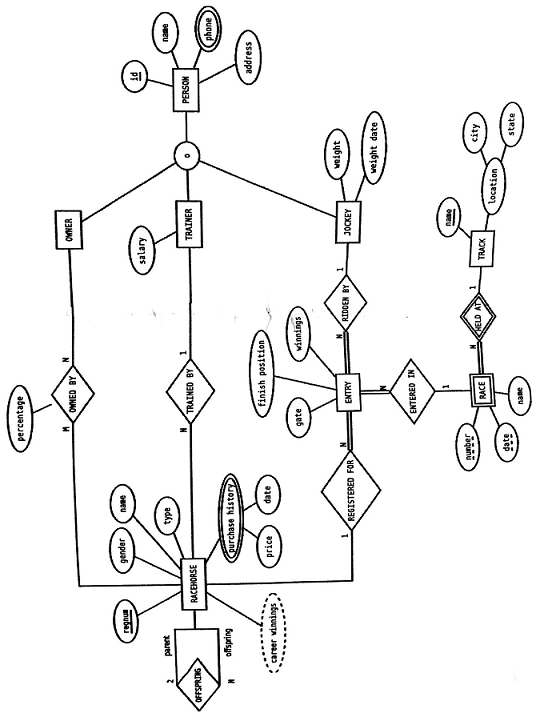
Draw an ER diagram which captures the requirements specified below as accurately as possible. Include participation, cardinality, and key constraints. If necessary specifics are lacking, make reasonable assumptions and state those assumptions. If there are any elements which cannot be represented in your diagram, identify them and explain what the problem is.
The Adventure Racing Ontario Series is a series of team-based adventure sports events taking place in Ontario, Canada. Teams earn points based on their race finishes over the course of a year, and series champions are crowned at the end of the year. After a few years of a manual spreadsheet-based points calculation system, the series organizers would like to move to a database-based application. Taking advantage of the opportunity to also expand the system to be able to track multiple point series at once, they have identified the following requirements:
- A point's series is identified by a name and year. For the purposes of series standings calculations, each series also has a point's limit and a threshold number of races.
- For each point series, a set of points rules define the maximum points possible for each kind of race. A rule consists of a race type (adventure race, adventure run, multisport, winter), minimum and maximum durations (optional), and the point value for that kind of race. Each rule is associated with a particular series.
- A race is identified by its name and date. A race also has a location (optional), type (adventure race, adventure run, multisport, winter), and (for adventure races) a duration. Duration is in hours e.g. 5, 8, 30. A race can belong to any number of point's series.
- Race entries can be individuals or a team, and are in a particular category (male, female, or coed). A team is made up of two or more individuals and must have a team name. Individuals can race on different teams for different races, and teams can have different rosters for different race. For the purposes of series results, the team name uniquely identifies a team.
- For individual racers, name, gender, birth year, and age are needed.
- Race results are recorded, in the form of each entry's placing (1st, 2nd; 3rd; etc) within their category.
- Race points, series points, and series standings for each individual and team are computed from the race results and point's rules, taking into account the points limit and threshold values for the series.
Question 2 -
Convert the following ER diagram to a relational schema. Be sure to specify any primary key, referential integrity (foreign key), and NOT NULL constraints. If there are elements of the diagram which cannot be expressed in your relational schema, identify them and explain what the problem is. Demonstrate good design principles; if there is a choice of ways to convert something, make a good choice and provide a rationale for your decision.
Questions 3-4 and 6-9 make use of the following relational schema:
EMPLOYEE( id, name, dept, title, salary)
TRIP(id, destination, departdate, returndate, employee)
EXPENSE (trip, item, code, date, amount)
CATEGORY(code, name, limit)
Key attributes are underlined. The foreign key constraints are:
TRIP.employee → EMPLOYEE.id
EXPENSE.trip → TRIP.id
EXPENSE.code → CATEGORY.code
A database with the name username_final will be made available so you can test your queries if you want.
For full credit, your queries must use only constructs legal in MySQL, work no matter what data is in the tables (do not rely on any particular instance), avoid producing duplicate rows where it is meaningful to do so (but duplicate-elimination has a cost and should not be used unnecessarily), and have a descriptive name for each column in the results.
Question 3 -
Write an SQL statement for each of the following.
(a) Find the destinations employees have traveled to.
(b) For each department, find the number of trips each employee took.
(c) Find the trips taken in 2016 with no single expense exceeding $1000. (The total expenses for the trip may exceed $1000.)
(d) Find trips where there is more than one expense in the same category on the same day.
(e) Find employees (id and name) with single expenses_ exceeding the limit for the expense's category.
(f) Find the most commonly used category code. (i.e. the one with the highest number of expenses) Report all such categories if there is more than one.
(g) Find the employees (id and name) who have expenses in every category.
(h) Find employees (id and name) and trips (id, destination, and departure date) where the total expenses for that person and trip exceed the category's limit in at least one category.
(i) Delete trips from past years (i.e. the return date was on or before 2016-12-31) which have no expenses.
Question 4 -
Write a stored routine which, given trip and expense information (employee name,_ destination, departure date, return date, item, code, expense date, amount), adds the trip to TRIP if it isn't already there and then adds the expense to EXPENSE. An error should be generated (and nothing changed in the database) if the employee does not exist or if there is more than one employee with the specified name.
Question 5 -
For each of the following, describe what it is, explain when it is appropriate/useful to use it, and Dive a scenario of how it could be employed in your final project. (This can be an example of how you did actually use the construct, or it can be an example of how the construct could be applicable within the domain of your project.)
(a) view
(b) trigger
(c) transaction
Questions 6-9 use the same schema as 3-4 with the following additional information.
Assume that the data files use fixed-length records with an unspanned organization. The block size is 1024 bytes, and a block pointer is 5 bytes long. There are 8 blocks of memory available.
Assume that files are ordered by primary key, and that there is a multilevel index on the primary key for each file.
The query optimization module of the DBMS has access to the following information about the tables:
|
EMPLOYEE
|
TRIP
|
|
number of rows
|
1000
|
number of rows
|
3000
|
|
column information
|
column information
|
|
id
|
2 bytes
|
1000 distinct values
|
id
|
4 bytes
|
3000 distinct values
|
|
name
|
46 bytes
|
|
destination
|
26 bytes
|
300 distinct values
|
|
dept
|
4 bytes
|
20 distinct values
|
departdate
|
3 bytes
|
2005-01-01 to
2017-12-31
|
|
title
|
41 bytes
|
40 distinct values
|
returndate
|
3 bytes
|
2005-01-01 to
2017-12-31
|
|
salary
|
3 bytes
|
30,000 to 150,000
|
employee
|
2 bytes
|
1000 distinct values
|
|
EXPENSE
|
CATEGORY
|
|
number of rows
|
15000
|
number of rows
|
10
|
|
column information
|
column information
|
|
trip
|
4 bytes
|
3000 distinct values
|
code
|
5 bytes
|
10 distinct values
|
|
item
|
26 bytes
|
50 distinct values
|
name
|
26 bytes
|
10 distinct values
|
|
code
|
5 bytes
|
10 distinct values
|
limit
|
4 bytes
|
0 to 10,000
|
|
date
|
3 bytes
|
2005-01-01 to 2017-12-31
|
|
|
|
|
amount
|
4 bytes
|
0 to 10,000
10% of the values are < 100
50% of the values are < 300
75% of the values are < 500
85% of the values are < 1000
95% of the values are < 2000
99% of the values are < 5000
|
|
|
|
Assume a uniform distribution of attribute values, except as indicated above for EXPENSE.amount.
Show your work for all computations! (what formulas your are applying, what numbers you are plugging in and where they came from, etc) If you need information that isn't provided or you don't know how to compute something, make a reasonable assumption about the value so that you can continue and clearly state your assumption. You will get very little credit for an answer without evidence of where it came from (even if it is correct), and if I can't follow your work, you won't get any credit if you make a math error or take a wrong step.
Question 6 -
Suppose that you have an index on date in EXPENSE.
(a) Is this index a primary index, a clustering index, or a secondary index? Explain.
(b) Compute the following values:
i. the size of an index record
ii. the number of index records
iii. the blocking factor for the index file
iv. the number of blocks in the first-level index (including indirect blocks, if any)
v. the number of levels in the index (for a multilevel index)
vi. the total number of index blocks for a multilevel index (including indirect blocks, if any)
Question 7 -
Consider the following query:
SELECT E.id,E.name,E.dept,X.trip,X.item,X.amount
FROM EMPLOYEE E, TRIP T, EXPENSE X
WHERE E.id=T.employee AND T.id=X.trip AND salary > 50000 AND code = 'food'
(a) Draw the query tree corresponding most directly to the query as stated.
(b) Apply heuristic optimization to your query tree from (a). Show your work - draw the query tree after each step of the heuristic optimization algorithm, label which step of the algorithm resulted in each tree, and provide a rationale for your actions in step 3.
Question 8 -
Consider the following query tree:
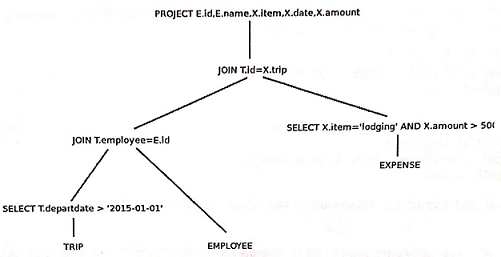
(a) Identify which of SL, SB, SH, SP, SC, and/or SS are applicable for each SELECT and which of JNL, JSL, and/or JSM are applicable for each JOIN. Include a brief explanation of your choices.
(b) Where there's a choice of algorithm, what choices do you expect to produce the best execution plan? Provide a rationale for your choices.
(c) State the cost of your execution plan from (b) in terms of the number of blocks read/written. Assume materialized execution (no pipelining).
Question 9 -
Consider three ways you might attempt to speed up execution of the query represented by the query tree in #9 -
(a) You can add an index. What additional index(es) could be useful? For each, identify the table indexed, the indexed attribute(s), and the kind of index (primary, clustering, secondary) and explain how it could be used.
(b) You can pipeline the execution of the plan. Identify where pipelining can be used in your plan from 9(b).
(c) You can rearrange the query tree. Give an equivalent query tree which allows for improvement in the execution plan, and explain your choice. Assume materialized execution (no pipelining).
(d) Which one of these three options do you expect to be most effective in reducing the number of blocks read/written for this query? Explain.
Question 10 -
Consider the following relation and functional dependencies;
PRODUCT(modelnum,year, price,manufacturer, plant, size, color)
- modelnum → manufacturer, plant
- modelnum, year → price
- size → color
(a) What normal form is this relation in? Explain your answer.
(b) Apply normalization until you cannot decompose the relations further. State the reasons behind each decomposition.
Question 11 -
A heuristic for optimization is to put the most selective SELECT operations lowest and leftmost in the query tree, but when you run
EXPLAIN SELECT *
FROM R STRAIGHT_JOIN S ON R.A=S.B
WHERE S.C=D
and
EXPLAIN SELECT *
FROM S STRAIGHT JOIN R ON R.A=S.B
WHERE S.C=D
You find that the first version has a lower cost. Explain why that could be the case.
Question 12 -
Is it ever advantageous not to use an index for carrying out a JOIN or SELECT operation when one is available? That is, could JNL have a lower cost than JSL? Could SL ever have a lower cost than SP, SC, or SS? Explain. (Consider both JOIN and SELECT.)