Part 1: 160-word critical reply with reference for this discussion post.
Hadoop Distributed File System is fault tolerant, it supports raid, (which stands for redundant array of independent discs) transfers of data between nodes, this is even when the system is overloaded and it fails, HBase ( which stands for Hadoop's data base ) is non-relational, column oriented and it runs on top of HDFS , it is opensource .
NoSQL databases runs top of Hadoop. HBase comes under types of databases that are called CAP types. This means that they are consistent, available and tolerant, they have large volumes of data in terms of gigabytes to zettabytes.
HBase is sophisticated in terms of its storage and data processes, this need sprung out of the exponential growth of data experienced in the last few years. Each cell includes a version attribute which is really a time stamp, versioning means it can retrieve any version of the attribute.
HDFS is suitable for batch analytics, its greatest weakness is not being able to do real time analytics, which are the trending requirements of the IT industry these days , HBase can handle large data sets and is not suitable for batch analytics , it is used to read and write data from Hadoop in real time .
Both HBase and HDFS have the ability to process structured, some structured and unstructured data.
HDFS had no in memory processing engine which slows it down when processing data, it is suited for real time environments, HBase is mainly a NoSQL database, it gets values through sorting them in in different key values
HBase's, map is indexed by a row key, column key and a time stamp
Part 2: 160-word critical reply with reference for this discussion post.
Initial post: How HBase query the data? What is its difference from SQL?
Hadoop and RDBMS are varying concepts of processing, retrieving and storing the data or information. While Hadoop is an open-source Apache project, RDBMS stands for Relational Database Management System. Hadoop framework has been written in Java which makes it scalable and makes it able to support applications that call for high performance standards. Hadoop framework enables the storage of large amounts of data on files systems of multiple computers.
Hadoop is configured to allow scalability from a single computer node to several thousands of nodes or independent workstations in a manner that the individual nodes utilize local computer storage CPU processing power and memory.
Database Management Systems focus on the data storage in table form which includes columns and rows. SQL is utilized to retrieve needed data which is stored in such tables. The RDBMS concept stores relationships between such tables in various forms so that one column of entries of a particular table will act as a reference for another table.
Such column values are known as primary keys and foreign keys with the keys being used to reference other existing tables so that the appropriate data can be related and also be retrieved by combining such tables using SQL queries as required. The tables and relationships can be altered by integrating relevant tables using SQL queries.
It is important to remember that Hadoop is not an actual database, although HBase and Impala can be considered as databases. Hadoop is just a file system known as Hadoop File System (HDFS) with built-in redundancy and parallelism. Traditional databases or RDBMS' have "ACID" properties which is an acronym that stands for Atomicity, Consistency, Isolation and Durability. These properties are not found at all in Hadoop.
For instance, if one has to script code for taking money from one particular bank to deposit the same into another bank then, they will have to painstakingly code all scenarios that may occur such as what happens when money is taken out but a failure results before it is moved into another account.
Part 3: 160-word critical reply with reference for this discussion post.
Explain the role of Object/Relational Mapping in bridging the technical differences in the PO application implementation - include limitations in dealing with inheritance, composition, aggregation, or generalization-specialization.
Object-relational mapping (ORM) is a programming technique in which a metadata descriptor is used to connect object code to a relational database. Object code is written in object-oriented programming (OOP) languages such as Java or C#. ORM converts data between type systems that are unable to coexist within relational databases and OOP languages. (Techopedia)
In bridging the technical differences in the PO application implementation, Object-Relational Mapping function in the following way; data stored in relational databases is represented to the application as objects in the native object programming language.
Programmers map domain object model classes to relational tables and use an Application Programming Interface(API) implemented by a persistence provider to access the database. Queries against the database are expressed in terms of the domain object model. The provider generates SQL statements directly from the domain model.
As noted by Scott M. "Not only must you map objects into the database, you must also map the relationships that the object is involved with, so they can be restored at a later date. There are four types of relationships that an object can be involved with: inheritance, association, aggregation, and composition.
To map these relationships effectively, we must understand the differences between them, how to implement relationships generally, and how to implement many-to-many relationships specifically."
Part 4: 160-word critical reply with reference for this discussion post.
Select and describe a simple application (other than a PO application discussed in A Sample Application using Object-Relational Features) in two different ways -- one designed as a relational database model and the second designed as an object model.
My model would be a gymnastics team database. It would be made up of the following entities and attributes in a relational model:
Family Entity - FamilyID, FamilyName, Address, City, State, Zip, HomePhone, CellPhone, WorkPhone, Email, MomFname, MomLname,
DadFname, DadLname
PaymentInfo - PaymentID, FamilyID, PayType
CreditInfo - PaymentID, CreditType, AccountNumber, ExpirationDate, CVVCode
BankInfo - PaymentID, BankName, RoutingNum, AccountNum, AccountType
Gymnast Entity - FamilyID, GymnastID, GFirstName, GLastName, DOB, Gender, StartDate, CurrLevel, Status
Coach Entity - CoachID, CoachFname, CoachLname, Address, City, State, Zip, HomePhone, CellPhone, Email, StartDate
Certifications Entity - CoachID, CertID, CertLevel, CertType, CompletedDate, ExpireDate
Levels Entity - GymnastID, LevelID, LevelName, LevelDate, HighScore, LastCompDate
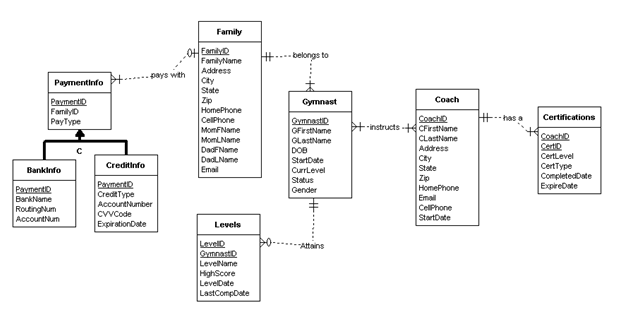
Transformation of this relational model into an object model would yield the following structures:
Family Object Type - contains familyID, familyName, Gymnast_type,Address_type, Phones_type, Emal_type
Coach Object Type - contains CoachID, CoachName, StartDate, Address_Type, Phones_Type, Cert_Type, Email_type
Payments Object Type - contains PaymentID, FamilyID, Payment_Type
Gymnast_type - includes nested table of GymnastID, Name, DOB, StartDate, Level_type, Status, gender
Address_type - includes Address, City, State, Zip
Phones_type - includes array of phone numbers
Email_type - includes array of email addresses
Payment_type - includes nested table of credit_type and bank_type