For this program, you'll be working with a set of text files to see if you can catch a plagiarist. This is a real-world problem that requires a software solution. Your program should (quickly) identify similarities between papers to identify cases where part or all of a paper was copied.
Here is adiagram showing similarities between documents; this is an actual set of physics lab assignments from a large university.
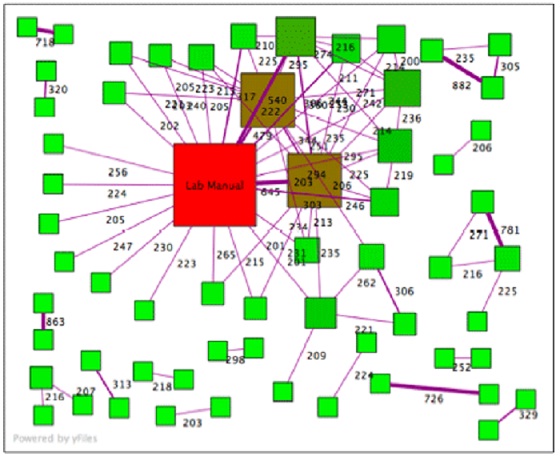
Each node (square) in the graph is a document. Each edge (line) connects two documents based on the number of 6-word phrases they have in common. To reduce noise, only documents sharing more than 200 6-word phrases are shown. The red square is the lab manual, and the brown squares are two sample lab reports that were distributed in class. (Apparently many students 'borrowed' heavily from these documents.) But if we look carefully, we notice that several papers share a large number of phrases in common with each other and with no other documents. For ex, a pair at the top left share 718, a pair at the top right show 882, and a pair on the lower left share 863 6-word phrases in common. It's likely that those people turned in essentially the same lab report or copied from each other.
Your program will read through a directory full of files and identify pairs of files that share more than 200 6-word phrases, as a means of detecting copied work.
It's important to understand what we mean by “6-word phrases.” It's not just looking at 6 words, then the next 6, etc.; after all, even plagiarists are smarter than that. A 6-word phrase is a word and the following 5 words, for each word with at least 5 words after it. So, for ex, the text:
Now is the time for all good men to come to the aid of their country. Contains the 6-word phrases:
Now is the time for all
is the time for all good
the time for all good men
time for all good men to
...and so on.
Thus, a single extended passage can generate many duplicates. On the other hand, a sentence that happens to begin with “Now is the time...” will be less likely to generate more than a few 'hits' as duplicate phrases. For our purposes, upper- or lower-case doesn't matter, nor does punctuation. You're given a data file containing about 25 (mostly very bad) high school papers downloaded from www.freeessays.cc.
You're welcome to add a few more papers from the same site if you want to see how well your program handles larger data sets. You should NOT hard-code file names, path names, or the number of papers into your code; your program will be tested against a different data set. Inside the directory containing your program, make a subfolder to hold the papers, and unzip the data file into it. Your program will ask the user for the name of the folder, verify that the folder exists (reprompt the user if it doesn't), read the files in it, and find the number of shared 6-word phrases between all possible pairs of files in that folder, reporting all pairs of files which have more than 200 such
phrases in common. Report the number of phrases in common, and both file names. When the program ends, the active (current or 'working') directory should be the same as it was when the program started.
Hints and development notes:
1) You can read an entire file into one big string, then split it on the spaces to produce a list of separate words. Likewise, you can convert strings to a consistent case, and either ignore punctuation or remove it.
2 A '6-word phrase' is six consecutive words found in the same order in both files. Spacing and capitalization are irrelevant.
3 A naïve approach would be to read in all files, break them up into phrases as needed, then use nested for loops to compare each file against every other. However, this ends up comparing each pair A and B twice; once when A is in the for loop, once when B is in it. Our measure is symmetric; if A shares 234 phrases with B, then B shares 234 phrases with A. Can you arrange things so each pair is only compared once?
4) You will make heavy use of the os and os.path modules in this program, to read directories, select files for reading, etc.
Other thoughts:
1) The number of pairs between N elements goes up as the square of N. This means that as the number of papers increases, performance will drop. If your program finishes the small data file in a few seconds, it may take several minutes (or more) to process a group of a hundred files, and hours or even days to process a set of a thousand files (even if you could hold everything you need in memory at once). Practical “real-world size” solutions to this problem may involve generating and storing temporary data that can be re-loaded if needed, or developing some sort of 'profile' of the text and then comparing profiles.
2) The combination of 200 hits and 6-word phrases is fairly arbitrary. You may want to experiment with other ranges to see how that affects the sensitivity of your detector.
3) Our approach is also very mechanical; a student who knew it was in use could make minor modifications to the plagiarized text and reduce the chances of being detected. Again, you may want to try paraphrasing rather than directly copying and see if it makes a difference to your detector.
4) Solving the plagiarism-detection problem quickly is, in general, a VERY difficult problem, especially using only the data structures we've covered so far. By all means, try out different approaches, but don't freak out if your solution doesn't scale up to a large data set well, or doesn't give the results you expected.
Sample run:
What's the name of the subfolder with the files? Documents You may want to examine the following files:
Files [filename1] and [filename2]
A total of 3 files are listed for this data set; names obscured to keep from making it too easy. --BKH